機械翻訳APIの中で最も優れているのはどれですか?


翻訳APIはどこにでもあります。 しかし、すべてが同じレベルのパフォーマンスを発揮するわけではありません。
最近の研究によると、すべての言語で勝者は1人ではなく、商用エンジンはオープンソースのエンジンと比較して優れたパフォーマンスを発揮します。
このベンチマーク調査では、Google、Amazon、Microsoft、DeepLなどのトッププレーヤーを対象に、ポルトガル語、中国語、日本語を含む7つの言語で20万以上の人間が翻訳したセグメントを使用してテストしました。
DeepLとAmazonがトップに立ちました。DeepLはヨーロッパ言語で優れており、Amazonはアジア言語でリードしています。
ほとんどのエンジンが迅速なレスポンスを提供する中、DeepLはリアルタイム翻訳のシナリオで遅れをとっており、遅延の中央値は1文あたり約1秒でした。 それは即時の結果に依存するアプリにとって大きなギャップです。
私たちは、BLEUスコアを人間の翻訳と比較して計算し、ターゲット言語やソース言語の文の長さなど、さまざまな側面を分析します。
さらに、リアルタイム翻訳を必要とする旅行アプリや翻訳会社のようなアプリケーションにとって重要な機能であるため、それらの翻訳APIの応答時間を測定します。

ですから、最適な翻訳APIを選ぶ際には、単に誰が最も多くの言語をサポートしているかだけではありません。 品質、スピード、コンテキストの間で正しいバランスを取ることについてです。
こちらが私たちの重要な見つけたことの要約です
- DeepLとAmazon Translateは全体的に最高の翻訳品質を提供しました。DeepLはヨーロッパの言語で優れており、Amazonは日本語や中国語のようなアジアの言語で優れています。
- 万能のエンジンはありません、パフォーマンスは言語ペア、文の長さ、翻訳の文脈によって異なります。
- 文章が長いほどすべてのエンジンでBLEUスコアが向上する傾向があり、これはテストしたすべての言語で一貫したパターンが観察されます。
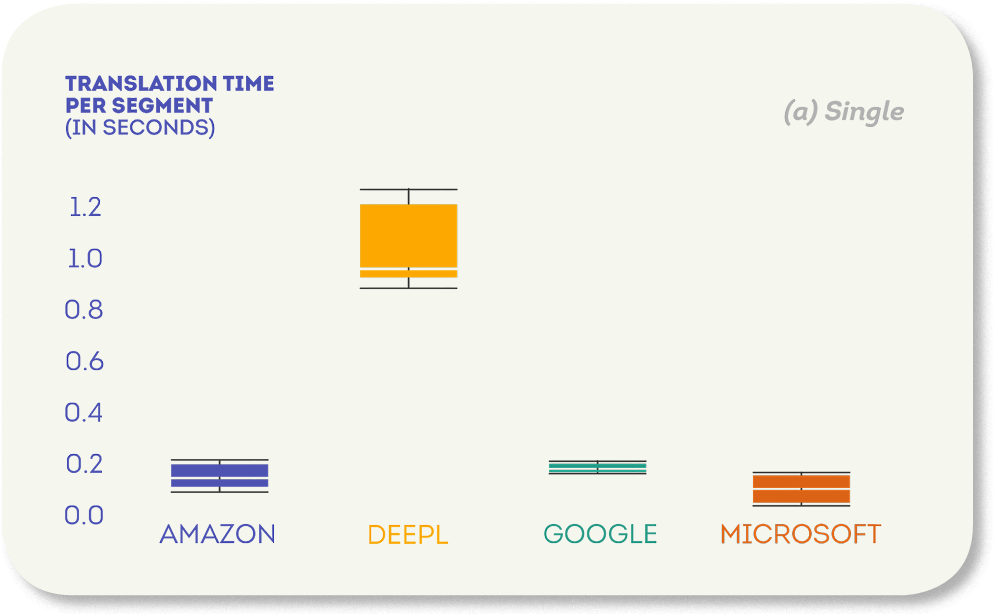
- Microsoft 翻訳者は単一セグメント翻訳で最速の応答時間を持っていました(中央値: 0.09秒)、一方DeepLが最も遅かった(1セグメントあたり1秒近く)。
- 一括翻訳モードでは、GoogleとMicrosoftはセグメントごとにサブセコンドの速度を提供しましたが、Amazonは真のバッチサポートがないため、パフォーマンスが劣りました。
- BLEUのスコアはエンジン間で統計的に有意な差を示し、フリードマンテストとネメニーテストによって確認され、逸話的な証拠を超えた結果を検証しました。
- スケーラビリティは等しくありません: DeepLの応答時間は、セグメントボリュームが増加すると急激に増加するため、大量のユースケースでは制限要因となる可能性があります。
- すべてのエンジンは、シングルコールモードのDeepLと一括シナリオのAmazonを除いて、リアルタイムアプリケーションで十分に機能しました。
- ブラジルのポルトガル語は、評価されたセグメントの数が最も多く、この調査で最も堅牢な言語ペアの1つとなっています。
- データの多様性が重要: 使用されたデータセットは、健康、法律、ITなどのドメインをカバーし、高い信頼性で実際の翻訳要求をシミュレートします。
機械翻訳APIとは何ですか?
機械翻訳APIは、開発者やプラットフォームが機械学習モデルを使用して自動的にテキストを言語間で翻訳できるようにするクラウドベースのサービスです。
企業は独自の翻訳エンジンをゼロから構築する代わりに、これらのAPIをウェブサイト、アプリ、または内部システムに統合して、迅速でスケーラブルな多言語コンテンツを提供できます。
最も人気のある機械翻訳APIのいくつかには以下が含まれます:
- Google 翻訳 API – 100 以上の言語をカバーし、Google Cloud と簡単に統合できます。
- Amazon Translate – 大規模で高速な翻訳用に設計されており、アジア言語での優れたパフォーマンスを発揮します。
- Microsoft 翻訳者 – 90以上の言語をサポートする、リアルタイムアプリケーションに最適な予算に優しいオプション。
- DeepL API – 特に流暢さとニュアンスにおいて、ヨーロッパ言語の高い品質の翻訳で知られています。
これらのAPIは、eコマース、旅行、法律、医療、顧客サポート、ローカリゼーションなどの業種で広く使用されており、正確でリアルタイムな翻訳がユーザーエクスペリエンスと業務効率を大幅に向上させることができます。
しかし、すべてのAPIが同じように作成されているわけではありません。そして、正しいAPIを選ぶことは、言語ペア、速度、コスト、そしてもちろん翻訳の品質など、あなたの特定のニーズに依存します。
機械翻訳エンジン
この評価では、私たちのデータセット内のすべての言語ペアをサポートする4つの商用機械翻訳エンジンを選択しました。 2022年1月時点の関連するコスト値とともに、以下で説明します。
- Amazon 翻訳: Amazonによって開発され、70以上の言語で機械翻訳のサポートを提供します。 そのPython APIはAWSサービスと完全に統合されており、100万文字あたり15米ドルの費用がかかります。
- DeepL: それは機械翻訳に注力している会社です。 APIは26の言語をサポートしており、100万文字ごとにUSD 25の費用がかかります。 私たちは、英語からの翻訳と英語への翻訳を可能にするPython APIを使用しました。
- Google翻訳: 100以上の言語に対して機械翻訳サポートを提供し、サポートされている言語に関して最も広範囲にわたるエンジンです。 また、すべての Google Cloud サービスに統合された Python API も提供します。 翻訳の価格設定は100万文字あたりUSD 20です。
- Microsoft 翻訳者: それは、すべての評価されたMTエンジンの中で最も低い価格設定で、100万文字あたり10米ドルのコストでMicrosoftが提供する機械翻訳サービスです。 このエンジンはほぼ90の言語をサポートしています。
選択されたMTエンジンは、それぞれのAPIを通じて単一のセグメントを翻訳することができ、Amazon Translateを除いて、セグメントのリストが送信され、一度に返される場合には一括呼び出しにも対応できます。
Amazon Translateの一括制限に対処するために、単一の呼び出しでマイナーなコーディング最適化を行い、毎回の翻訳でAPIへの接続を確立する必要を排除しました。これは一括翻訳には近くありませんが、一括翻訳サポートを持つ他のエンジンとのギャップを縮めるのに役立ちました。
言及されたすべてのMTエンジンは、特定の用語のための並列データや用語集でモデルを調整するのに適していましたが、今回の評価ではこれらのオプションを除外することにしました。
また、他のMTエンジン(例:Baidu Translate、Tencent、Systram PNMT、Apertium、Alibaba)の評価も試みましたが、以下の理由のいずれかで使用できませんでした:
- APIの利用不可
- ドキュメントの不足,
- すべてのターゲット言語に対するサポートがない。
Metrics
私たちは、BLEUスコア(Papineni et al., 2002)を使用してエンジンの翻訳品質を評価します。 Friedmanの検定(Friedman, 1940)を使用して異なるエンジンのスコアを比較し、事後的なNemenyi検定(Nemenyi, 1963)を使用して、個々のMTエンジン間の統計的有意差を検証しました。
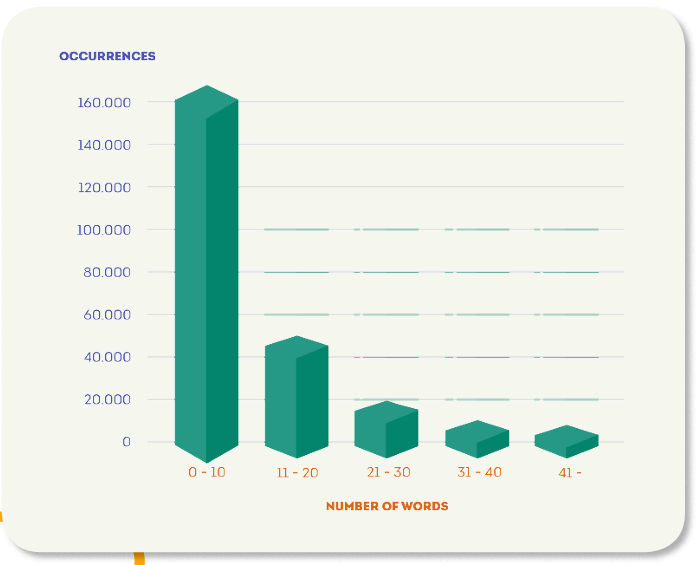
API の応答時間を計算するために、セグメントサイズの間隔の分布を考慮して、データセットから100のセグメントをサンプルとして選択し(図2)、各エンジンで英語からポルトガル語に翻訳しました。
選択した文を 1 日 1 回、1 週間かけてエンジンにヒットし、API のメソッド (single と bulk) を評価します。 データセット全体を使用せず、レスポンスタイムを評価するために1つのターゲット言語のみに翻訳しました。これは、7つの言語で20万のセグメントを1週間エンジンにかけると、金銭的に高額になるためです。
実験結果
このセクションでは、第2節で説明した機械翻訳エンジンの性能に関する調査結果を示します。
品質評価
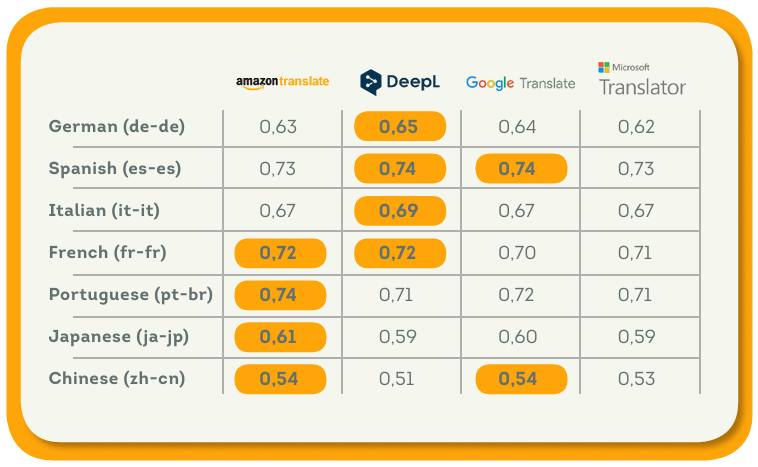
以下の表は、各ターゲット言語における4つのエンジンの平均BLEUスコアを示しています。 すべての言語について、Friedmanの検定のp値は有意水準(0.05)よりも小さく、エンジンのスコアに統計的に有意な差があることを意味しています。 さらに、各言語で最高スコアを持つエンジンは、p値が有意水準の0.05より低いポストホックNemenyi検定によると、他のエンジンと統計的に異なるパフォーマンスを示しました。 AmazonとDeepLは、4つのターゲット言語で最高得点を獲得し、総合的に最高の結果を達成しました。 Googleはスペイン語でDeepL、中国語でAmazonと並びましたが、Microsoftの翻訳エンジンはどの言語でも他のMTエンジンを上回ることはありませんでした。
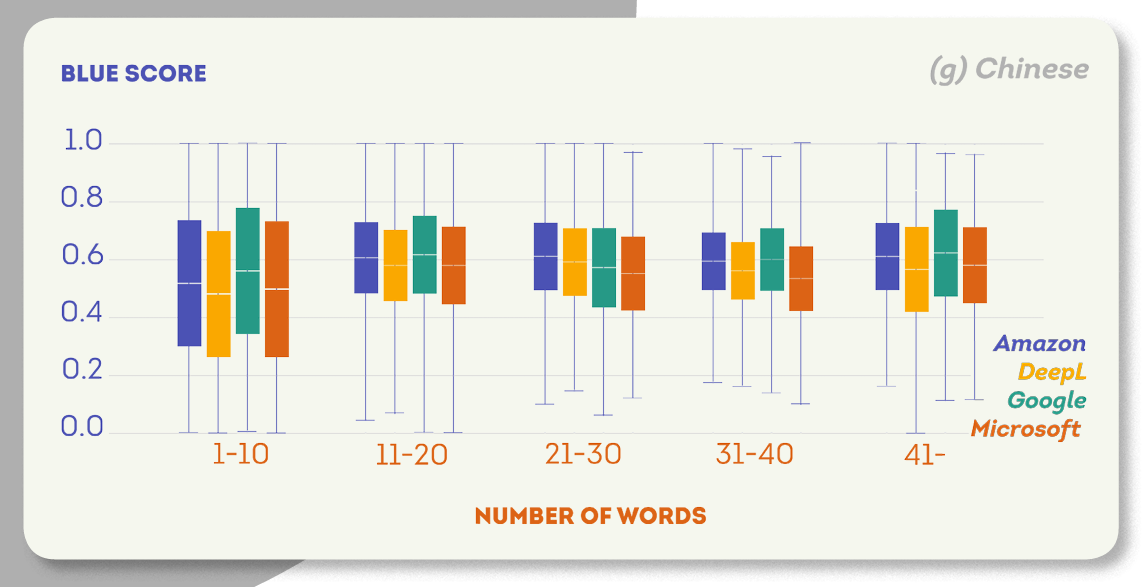
次の図は、各ターゲット言語のさまざまなセグメントサイズのBLEUスコア分布を示しています。 これらのプロットに共通する傾向は、文が長いほどBLEUスコアが高くなることです。
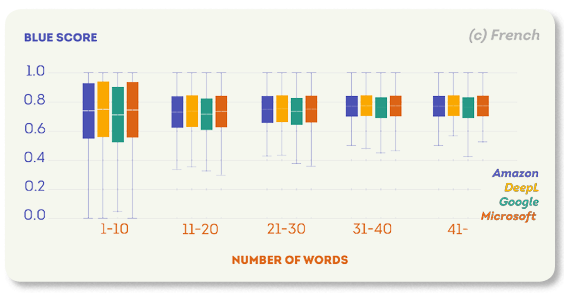
例えば、ドイツ語をターゲット言語とするすべてのMTエンジンのスコアの中央値は、サイズが1から10までのセグメントで約0.6、40ワードを超えるセグメントで0.7に近いものでした。
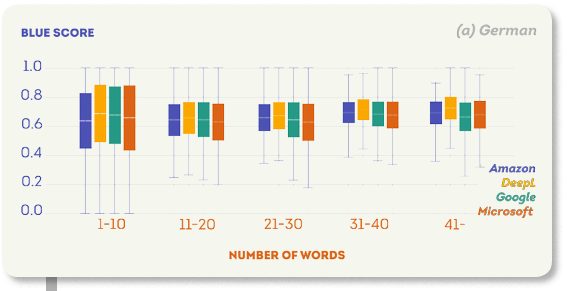
日本語は唯一の例外です: セグメントサイズはAmazonとDeepLの翻訳品質には影響しませんでしたが、Microsoft(1-10区間の中央値BLUEスコアは0.61、40-区間は0.58)とGoogle(1-10区間の中央値BLUEスコアは0.62、40-区間は0.6)の品質には影響しました。
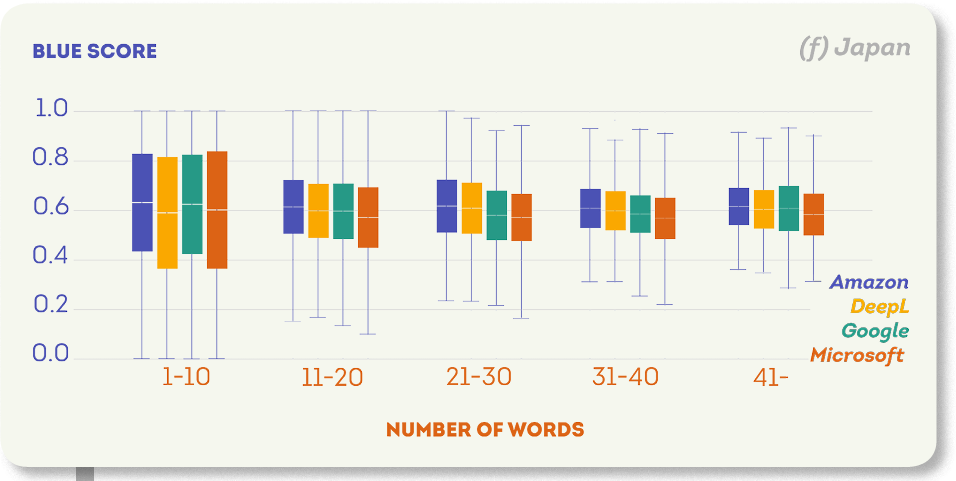
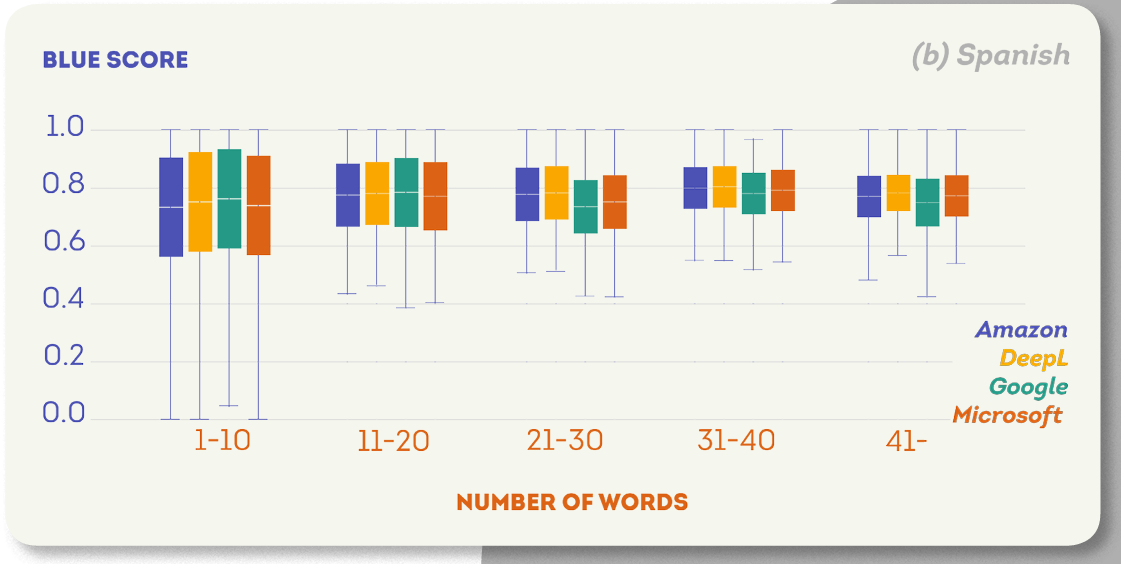
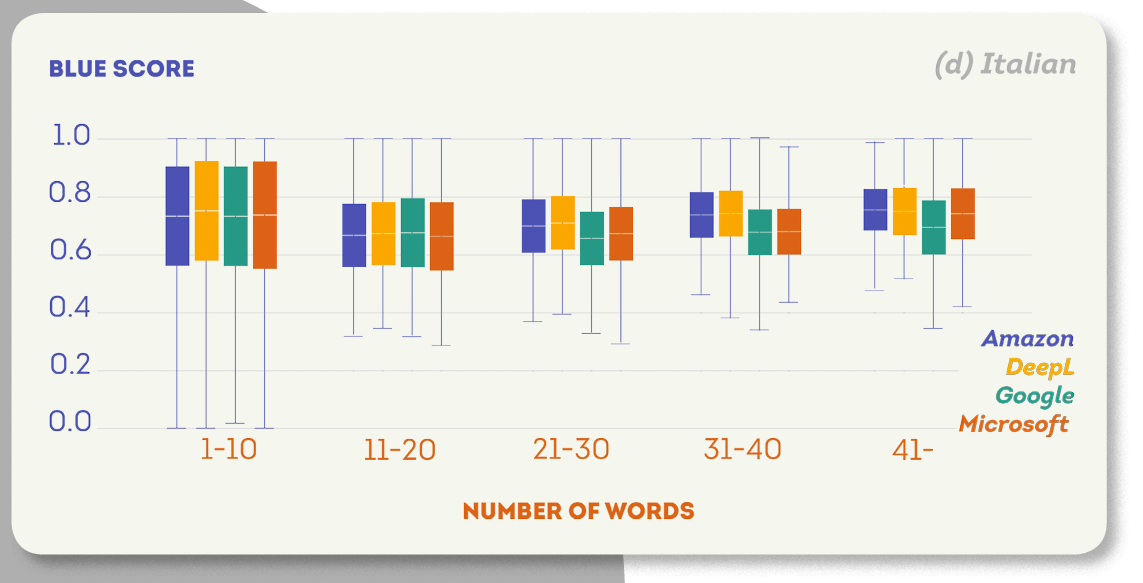
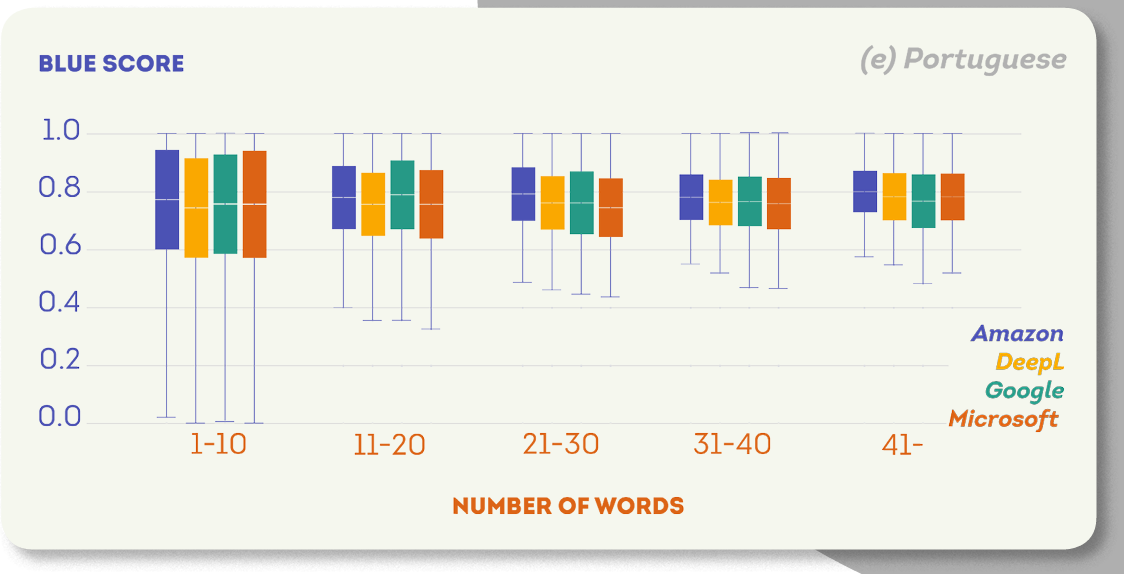
翻訳時間評価
MTエンジンごとに、1セグメントずつ送信する場合(単一)と100セグメントを一括で送信する場合(バルク)の、セグメントごとの翻訳時間の分布を以下で分析できます。
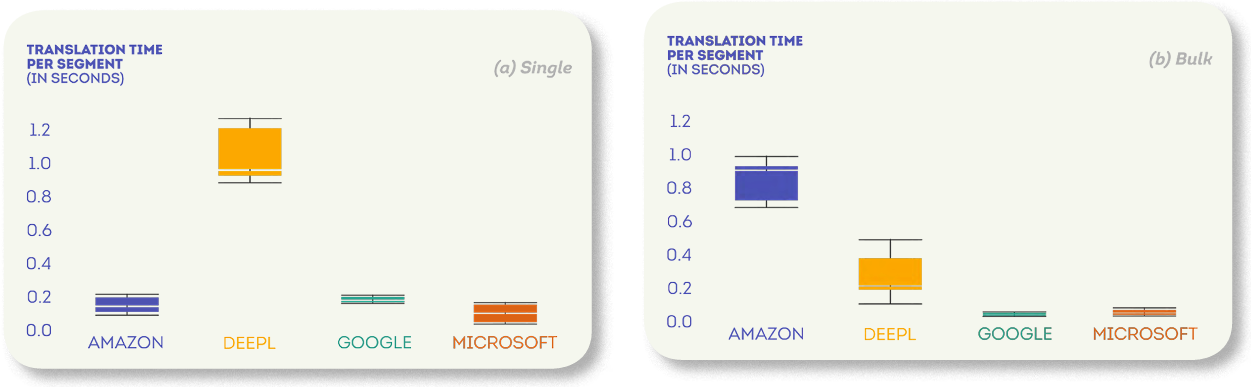
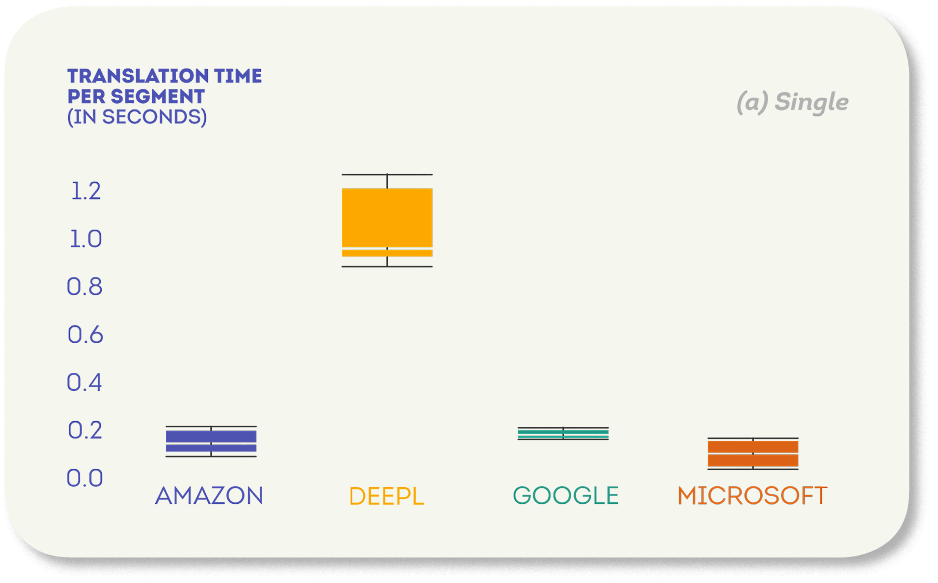
1 つのシナリオでは、Microsoft が最速の翻訳を提供しました (セグメントあたり中央値 0.09 秒)。 AmazonとGoogleは約2倍遅く(中央値は0.2秒近く)、DeepLは最も遅く(セグメントあたりの中央値は0.96秒)で、Microsoftの約10倍でした。
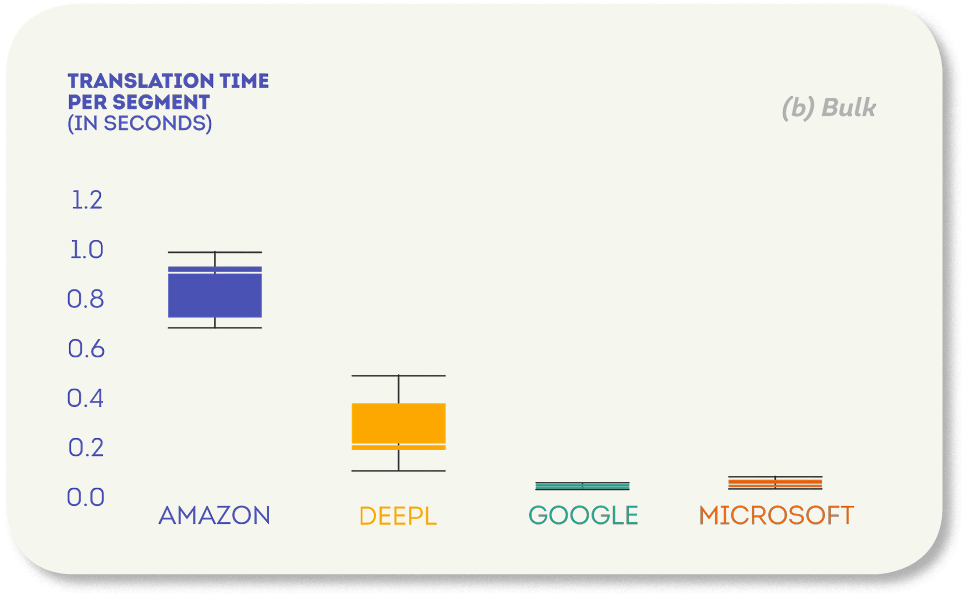
API の一括呼び出しを単一の呼び出しと比較して使用すると、最初に気付くのは、セグメントあたりの翻訳時間が大幅に短縮されたことです。 例えば、DeepLでは、セグメントあたりの翻訳時間の中央値が、単一実行では0.95秒から一括実行では0.02秒に短縮されました。
これらの結果は、セグメントを個別に翻訳するよりも、一括操作の方がはるかに効率的であることを明確に示しています。 エンジンの個々のパフォーマンスに関しては、MicrosoftとGoogleが最も低い翻訳時間(それぞれセグメントあたり中央値0.003秒と0.002秒)を記録しましたが、最も高い翻訳時間はAmazonで(中央値0.09秒)した。
Amazonのこのパフォーマンスの低さの理由は、実際の一括呼び出しを提供していないことにあると考えています。これは、前述のように実験で近似する必要がありました。
したがって、評価されたMTエンジンは、セグメントあたりの翻訳時間が短く、リアルタイム翻訳アプリケーションに適しています。 唯一の例外は、1つの文の翻訳時間の中央値が1秒に近い単一のシナリオでのDeepLでした。
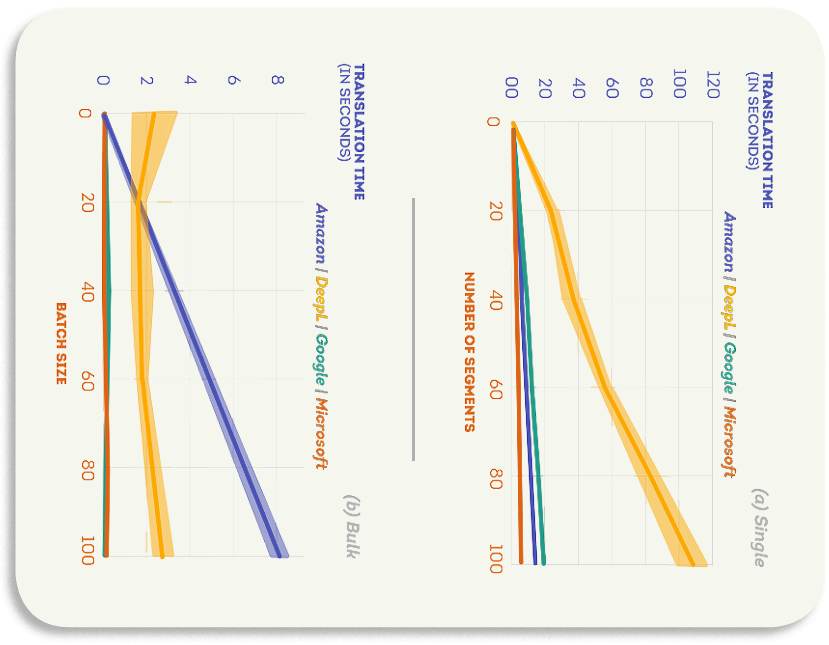
エンジンのスケーラビリティを分析するために、セグメントの数を変更した場合のMTエンジンの応答時間を以下に示します。 すべての曲線で、時間はセグメントの数に比例して増加します。
ただし、一部のエンジンの線形係数は、他のエンジンよりもはるかに小さくなっています。 例えば、DeepLは単一シナリオで最も高い係数を持ち、Amazonはバルクシナリオで最も高い係数を持っているため、それぞれのシナリオで競合他社ほどスケールしないことを意味します。
Conclusion
この論文では、4つの機械翻訳エンジンの品質と応答時間に関する評価を提示しました。 私たちの評価では、エンジンの品質は似ていることが示されましたが、AmazonとDeeplがトップパフォーマーとして挙げられました。 応答時間については、全体的にエンジンは良好なパフォーマンスを示しましたが、DeepLは一度に1つのセグメントを送信した場合、Amazonはバッチコールで例外がありました。
実験のセットアップ
このセクションでは、実験評価で使用したセットアップを紹介します。 より具体的には、我々はグラウンドトゥルースデータセット、機械翻訳エンジン、およびエンジンを評価するために使用される指標について説明します。
データ
この評価で使用されたデータセットは、プロの翻訳者によって生成された異なる企業の13の翻訳メモリからのもので、英語をソース言語とし、7つのターゲット言語があります:
- ドイツ語 (de)
- スペイン語 (sp)
- フランス語 (fr)
- イタリア語 (it)
- 日本語 (ja)
- ブラジルポルトガル語 (pt)
- 中国語 (zh)
英語のすべての文には、少なくとも1つの対応するペアが、言及されたターゲット言語のいずれかとあります。 データセットには、英語で合計 224,223 のセグメントと 315,073 のペアがあります。
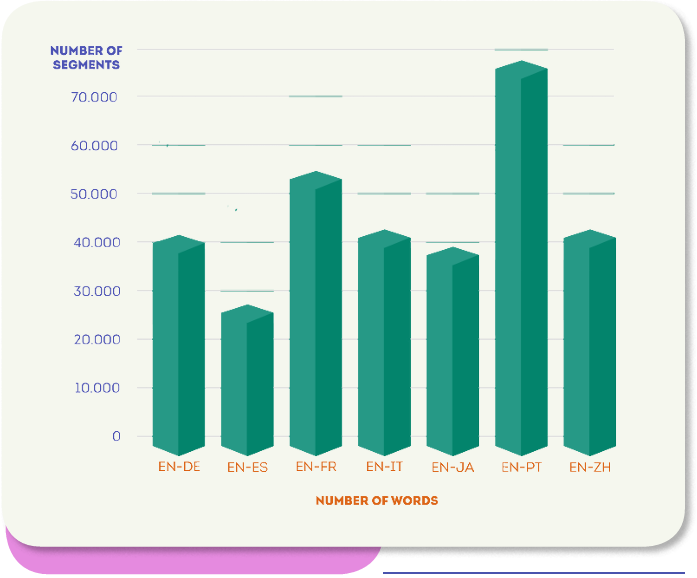
次の図は、各ターゲット言語のセグメント数の分布を示しています。 ブラジルのポルトガル語はセグメント数が最も多く(約60k)、日本語とスペイン語は最も少なく、約20kセグメントです。 この評価のためのこのデータセットの重要な特徴は、非常に多様なトピックをカバーしていることです。
次の図は、英語セグメントのワードクラウドを示しています。 ご覧のとおり、健康、法律、情報技術などに関連するコンテンツがあります。
データセットは、ソース言語のテキストセグメントと、ターゲット言語の翻訳を含む参照リストで構成されています。 これらの参照リストには、元のテキストに関連付けられた翻訳が少なくとも1つありますが、1つのセグメントに複数の翻訳が含まれる場合があるため、複数の翻訳が含まれることもあります。
私たちの分析を簡素化するために、以下の図に示されているように、セグメントをサイズ10の範囲にグループ化し、エンジンの翻訳の品質に対するセグメントサイズの影響を評価しました。
この論文は…
翻訳を導入しようとしているすべての企業は、この論文を読む必要があります。なぜなら、各機械翻訳ツールの品質と応答時間に関するさまざまな利点と欠点を概説しているからです。 この詳細なコンテンツは、翻訳関連の製品やサービスの改善に積極的に関与している専門家を対象としています。
- プロダクトマネージャー,
- プロジェクトマネージャー,
- ローカライゼーションマネージャー,
- エンジニアリングリーダー,
- 翻訳者,
- 翻訳会社.
この論文はwxrksのエンジニアによって書かれました。
wxrksは、詳細なレポート作成、進化する翻訳メモリ、自動化されたローカリゼーションを可能にするローカリゼーションプラットフォーム上で、包括的な社内翻訳サービスを提供します。
最も重要なことは、ローカリゼーションのビジネス要素と技術要素を1つの屋根の下に組み合わせていることです。
ガブリエル・メロ、ルチアーノ・バルボサ、フィリペ・デ・メネゼス、バニルソン・ブレジオ、エンリケ・カブラル。
ビューローワークス、Universidade FederaL de Pernambuco、Universidade FederaL RuraL de Pernambuco
3685 Mt DiabLo BLvd、ラファイエット、CA、アメリカ合衆国、Av. プロフ・モラエス・レゴ、1235、レシフェ、PE、ブラジル、ルア・ドン・マヌエル・デ・メデイロス、s/n、レシフェ、PE、ブラジル
3685 マウント・ディアブロ・ブルバード、ラファイエット、CA、アメリカ合衆国、アベニュー。 モラエス・レゴ教授、1235、レシフェ、PE、ブラジル、ルア・ドン・マヌエル・デ・メデイロス、s/n、レシフェ、PE、ブラジル
{gabrieL.meLo, fiLipe, henrique}@bureauworks.com Luciano@cin.ufpe.br、vaniLson.buregio@ufrpe.br
Unlock the power of glocalization with our Translation Management System.
Unlock the power of
with our Translation Management System.







.svg)
.svg)
